
大佬有实现的思路了吗
一般的平台可能都会有一个 “字典维护” 模块。这个模块包含的功能有字典分类维护、字典数据维护。通过字典维护模块来维护系统中用到字典数据,比如籍贯、职务、文化程度、 国籍等。
但是 CUBA 平台不提供类似的基础功能,我想大概是因为在 CUBA 平台中实现这样的功能太容易。这里我推荐一种实现思路。
我们知道所有的字典数据基本包含相同的要素,比如内部代码、显示名称、是否禁用、对于用户是否可见、显示顺序、拼音助词码。 一般的框架都是基于原生SQL进行开发,所以开发人员会想到设计一个数据库表来存储所有字典数据,给表中添加一个字典分类字段来区分是哪种字典。 CUBA 框架的数据访问主要是基于 JPA, 所以我们需要用 JPA 手法设计:
- 先设计一个基础字典实体,这个实体中包含所有通用属性
参考实现如下,实体名是 KVDictionaryBase:
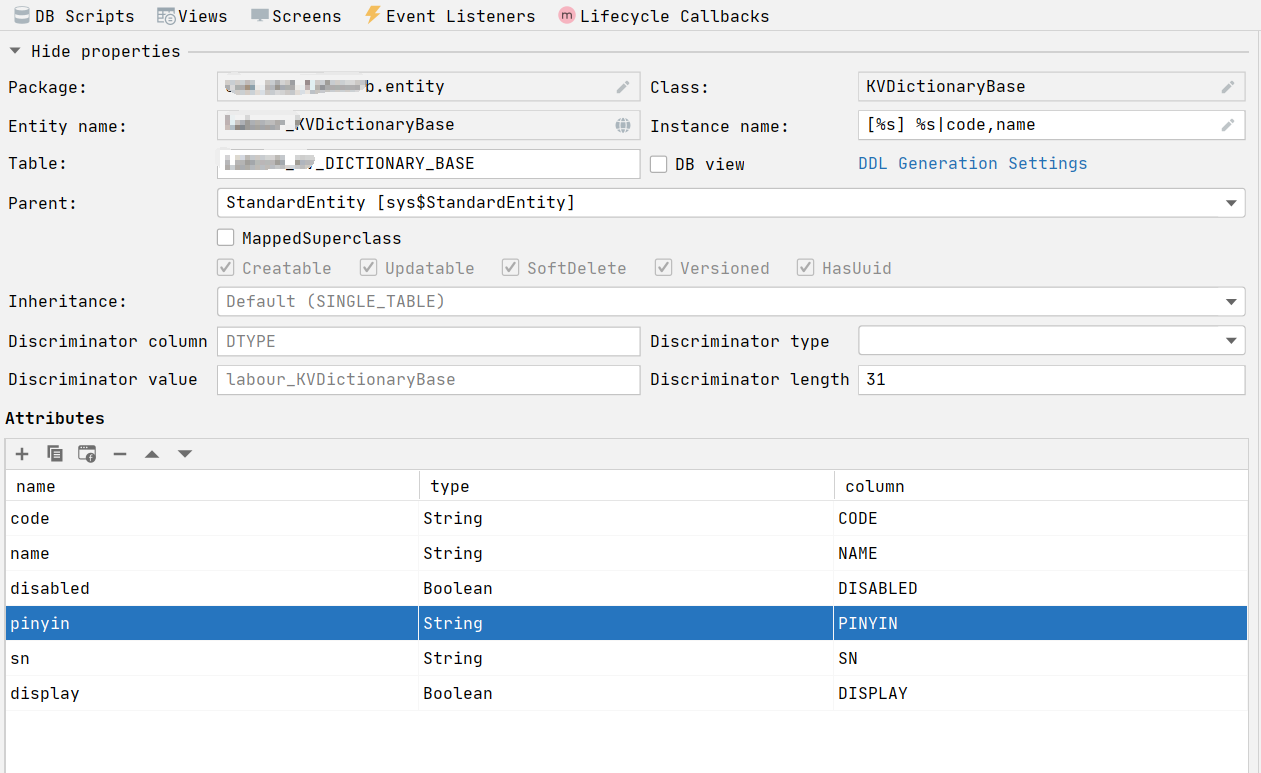
在实体设计器界面,有几个设置需要注意一下:
-
MappedSupperClass
不选中此项:表示基础实体类不对应一个数据库表,只是用于定义实体类的公共属性 -
Inheritance
这个属性表示实体类的继承策略,主要是指实体类对应的数据库表如何创建。这里选择 SINGLE_TALBE, 即每个子实体对应一个表,即每种类型的字典数据存在在一个独立的表中。
-
对于每个具体的字典类型创建一个子实体,比如下面是国籍字典的实现:
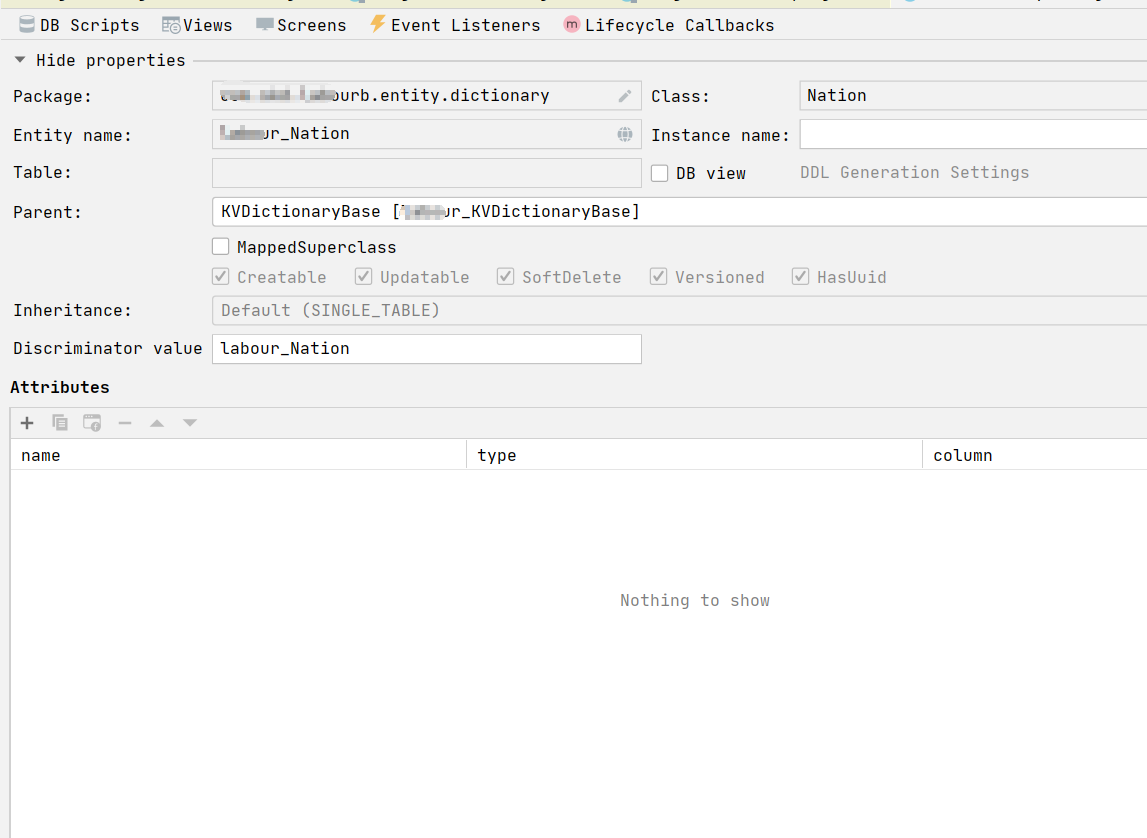
一般情况下,这个子实体中不需要定义任何属性,除非这个字典有特别的属性需要设置。 我们的一个系统中字典实体定义如下:
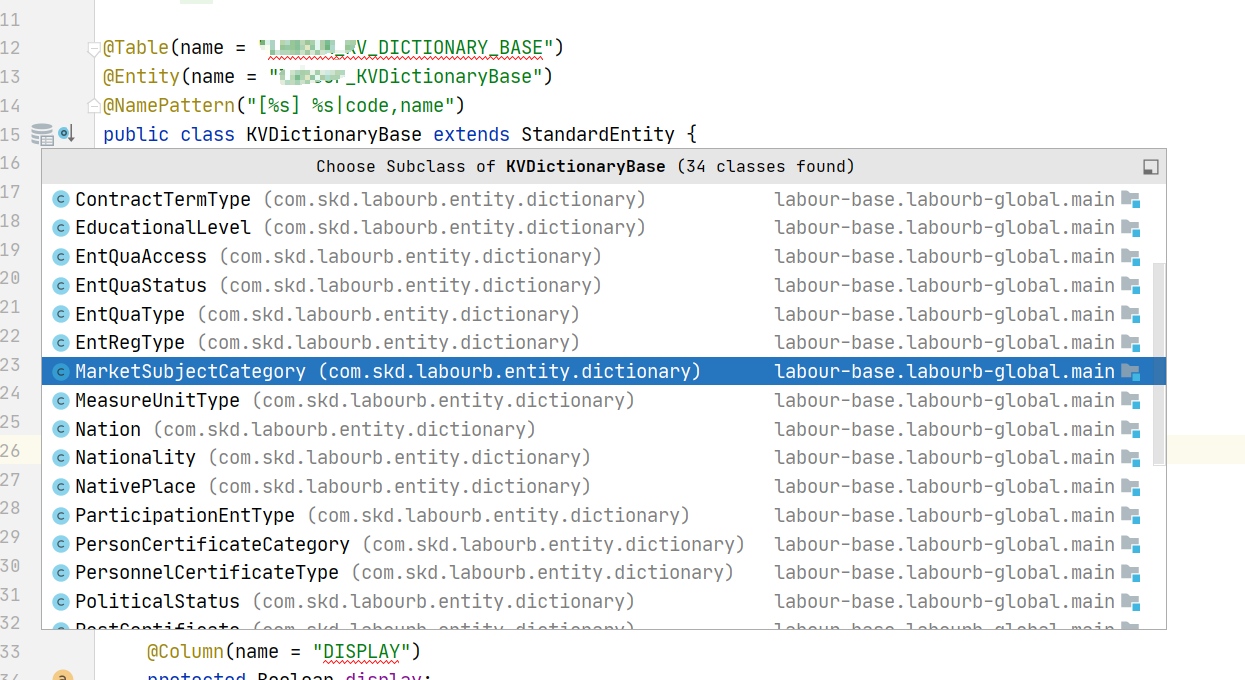
我们可以看到基础字典实体 KVDictionaryBase 有34个子类。 -
创建字典维护界面
有两种方式:
- 使用 CUBA 框架的”实体探查“机制
CUBA 框架的实体探查可以根据实体定义生成增、删改查的维护界面。这种方式能满足绝大部分字典维护需求。关于实体探查功能的使用,参考实体探查。 - 使用 CUBA Studio 界面向导生成增删改查的界面
如果你需要对某种类型的字典维护界面进行个性化定制,可以使用这种方式。
第三个步骤不是必须的,因为 CUBA 框架提供了通用的”实体探查“功能,通过这个功能你可以维护所有实体数据。如果你的字典数据仅由管理员维护,那么就没必要再去考虑字典实体的维护界面。
好了,在 CUBA 中两、三步即可实现一个可扩展、可定制的字典维护功能,这个过程几乎不需要编码。
2 个赞
好的,谢谢您的回复,我大致了解了。
你可能没有看到完整版,我刚编辑完。 